To finalise making the algorithm more generic, I’ve taken a new approach to the thresholding step I used to help identify the corners.
Instead of a single step, I repeatedly loop through and attempt to identify the corners with an increasing threshold. The loop ends either when 4 corners are identified, or a maximum have been reached
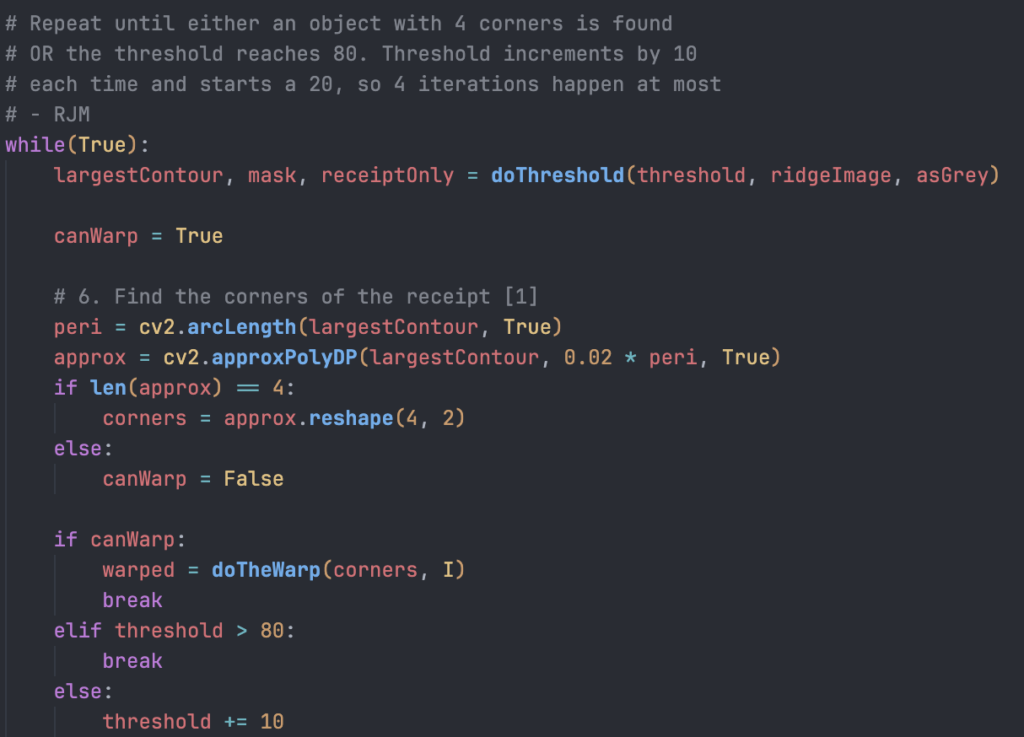
This allows a higher chance of being able to warp the receipt. Though, if a receipt cannot be identified (I.e. Not all four corners can be found), the original image is passed on to the next stages implemented by Dáithí and Jim.
This marks the end of this project, which was quite fun. I really enjoy new challenges and a non-ML approach to image processing was really fun!
Huge thanks to Jack O’Neill and Jane Courtney for the module, as well as Dáithí O’Flynn and Jim Lawlor for being the best teammates one could wish for.

An example of another receipt being straightened

As well as a receipt that didn’t need much warping
